.

Illustration adopted from Allison Horst
R Objects
You can consider R objects as saving information
e.g., text, number, matrix, vectro, dataframe
In another words everything in R is an object

R packages

Importing data into R
SPSS, Stata & SAS using haven package

Importing data into R
Excel files using readxl package
# A tibble: 150 × 5
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
<dbl> <dbl> <dbl> <dbl> <chr>
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
# ℹ 140 more rows
Importing data into R
CSV files using readr package

Basic data wrangling with Tidyverse

What is tidyverse?
A collection of R packages designed for data science.
All packages share an underlying philosophy, grammar, and data structure.
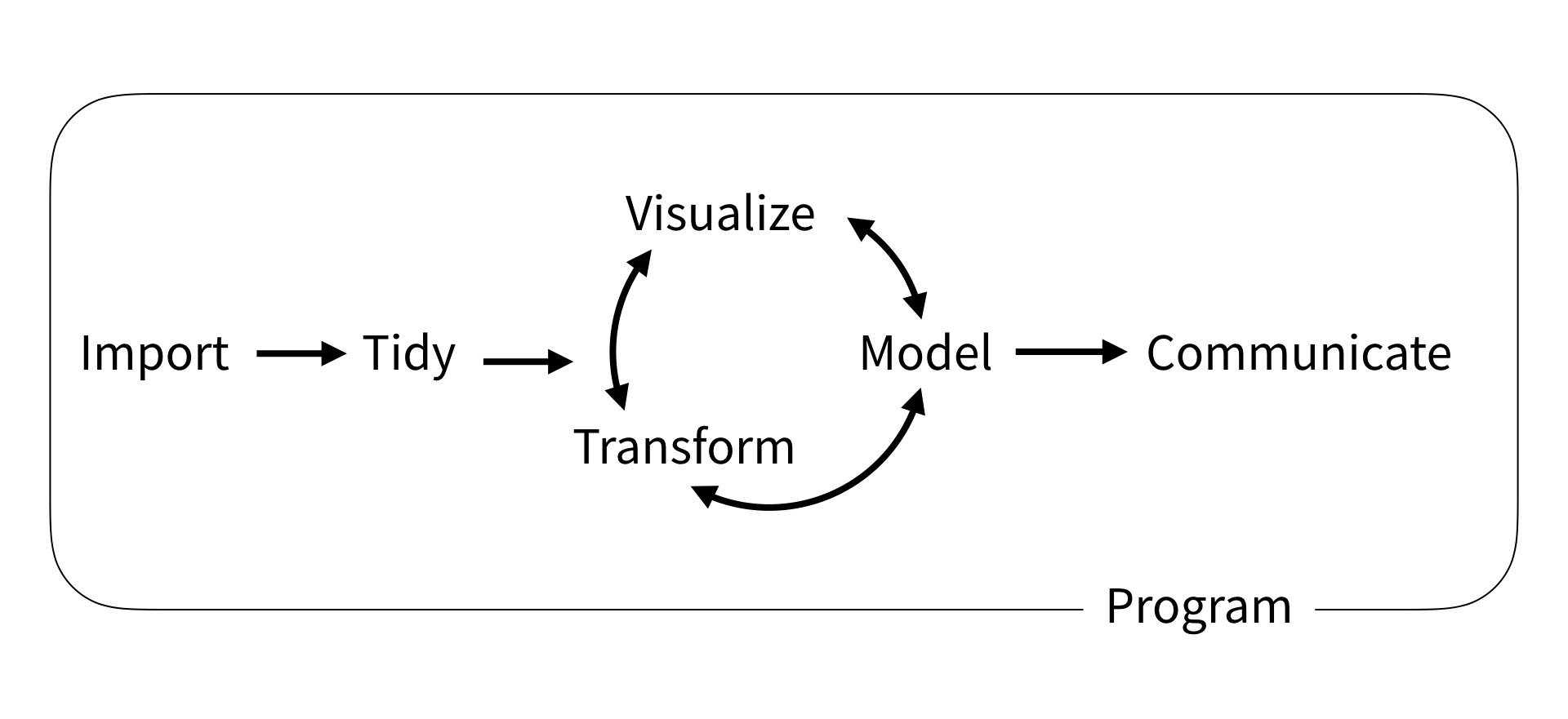

Illustration adopted from Allison Horst
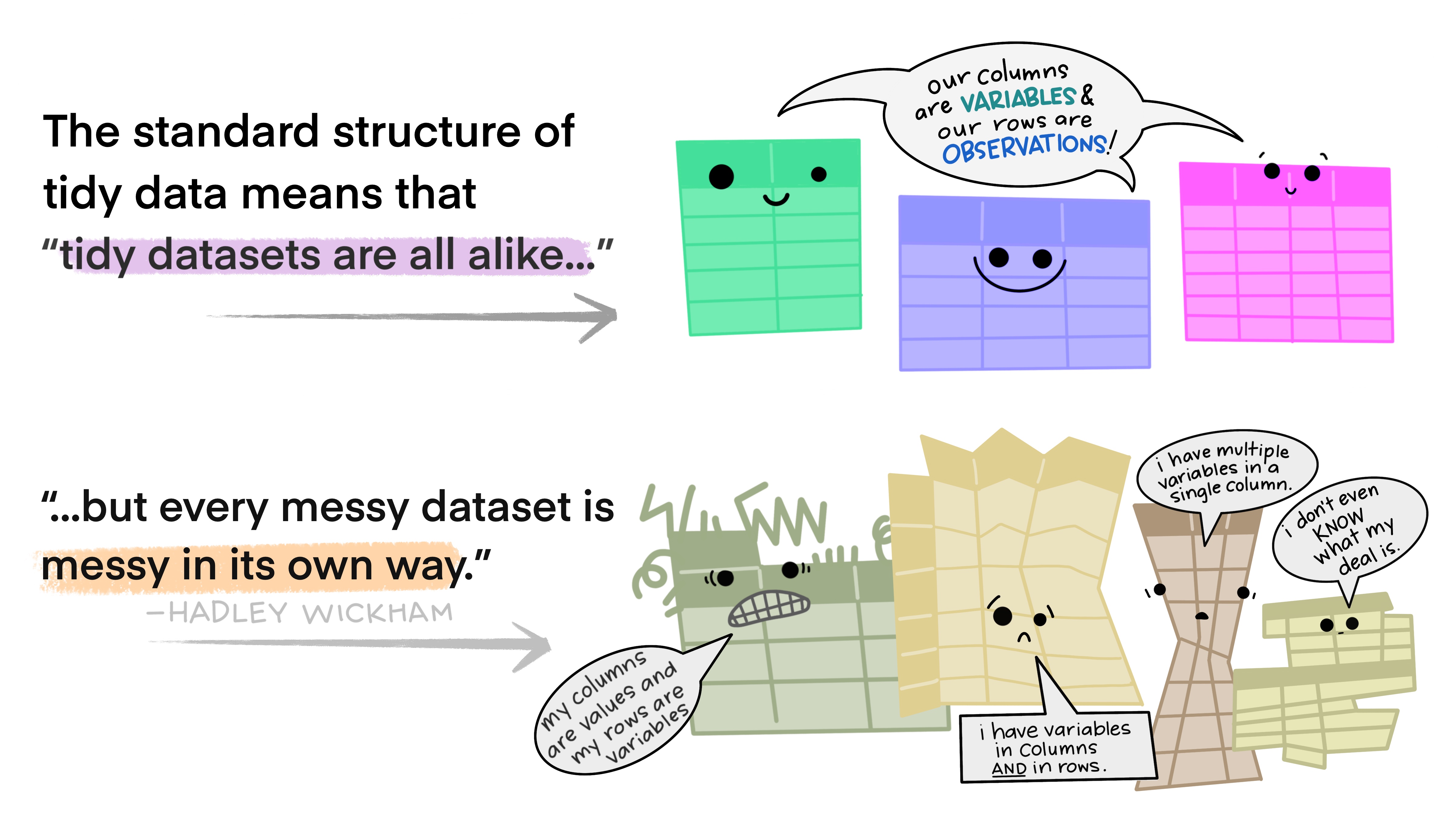
Illustration adopted from Allison Horst
Tidy data makes it easier for reproducibility and reuse
Illustration adopted from Allison Horst
Yehey! Tidy Data for the win!

Illustration adopted from Allison Horst
Data wrangling using dplyr

Illustration adopted from Allison Horst
dplyr
Overview
select()picks variables based on their namesmutate()adds new variablesfilter()picks cases based on their valuessummarise()reduces multiple values down to a single summaryarrange()change the ordering of the rows

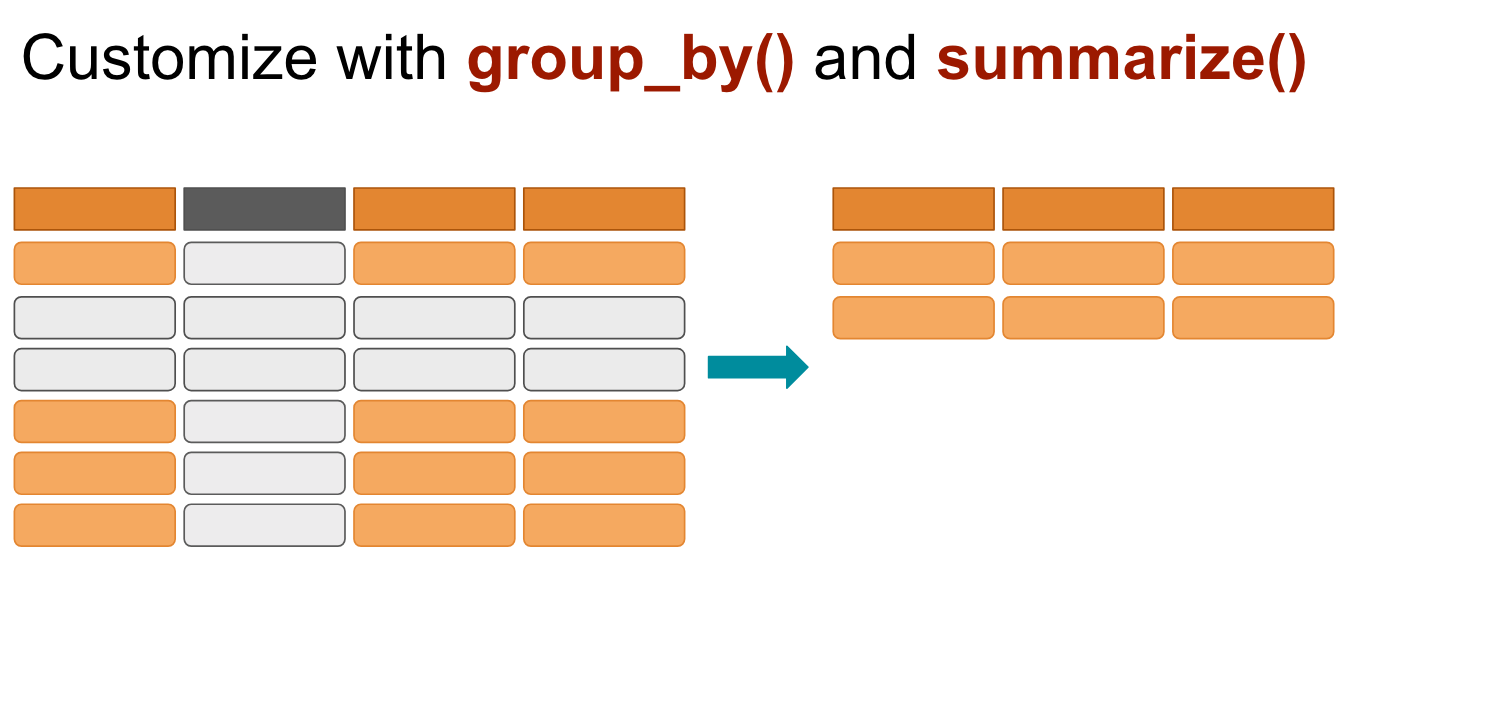
group_by and summarise()
Use when you want to aggregate your data (by groups).
Sometimes we want to calculate group statistics.
Too many codes!
It’s hard to follow!
It’s hard to keep track of the codes!


%>% pipe operator
![]()